Sources#
Summary#
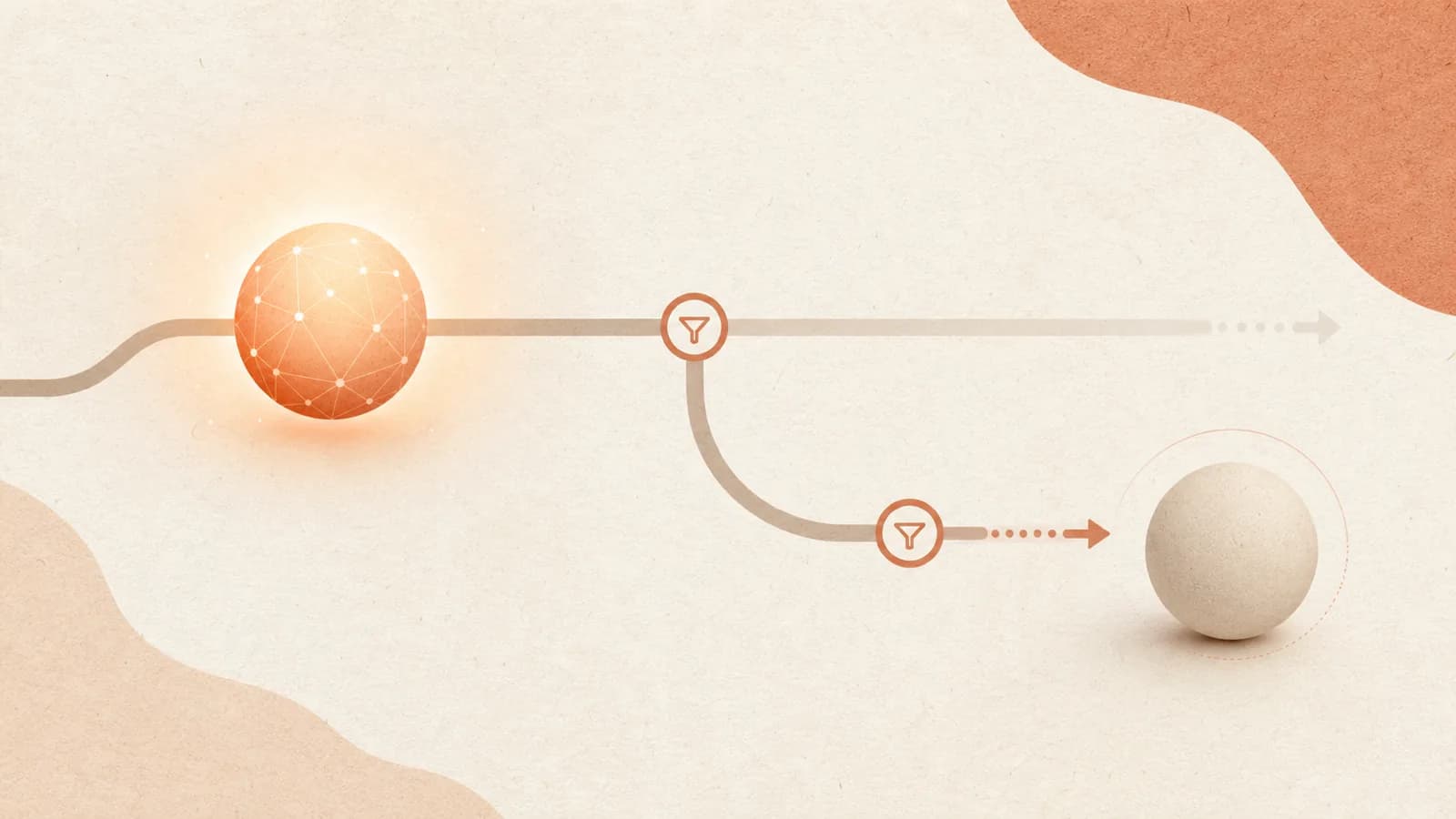
The safeguard architecture that lets Anthropic ship a Mythos-class model for general use: when separate AI classifiers detect a query in a high-risk dual-use domain (cybersecurity, biology & chemistry, or distillation), the response is automatically handled by a less-capable model — Claude Opus 4.8 — instead of Fable 5 refusing. The user is told whenever this happens. Anthropic's framing: "a response that falls back to Opus is a far better experience than an outright refusal." More than 95% of Fable sessions involve no fallback at all; the classifiers are tuned conservatively (they "sometimes catch harmless requests," triggering in "less than 5% of sessions"), accepting false positives as the price of a fast, safe release.
This is a distinct point on the safeguard spectrum. Mythos Preview was gated entirely (preview-only); Opus 4.7 differentially trained down cyber capability and blocked at inference; Fable 5 keeps the full capability in the model but interposes a classifier that swaps in a weaker model on risky topics. The capability is preserved for the >95% benign case and routed around for the rest.
Why "fallback, not refusal"#
The motivating fact is uplift: Mythos-class models could give malicious actors cyber/bio assistance "they couldn't have received from other sources." And much advanced usage is dual-use — the same query is beneficial for a defender or a researcher and dangerous for an attacker. A blanket refusal is both a bad user experience and, because it leaks which queries are "dangerous," an information signal. Falling back to Opus 4.8 — itself a highly capable model — degrades gracefully: the user still gets a competent answer, just not a Mythos-class one, on the flagged topic.
The three classifier domains#
- Cybersecurity. Covers both exploitation and offensive cyber tasks broadly (reconnaissance, discovery, lateral movement — see LLM-Driven Vulnerability Research). In a blocking-mode evaluation, "our classifiers prevent Fable from making any progress on these tasks." One external partner found Fable 5's cyber safeguards the most robust of any model tested (including Opus 4.8 and 4.7): Fable complied with zero harmful single-turn requests on cyberattack planning, exploit development, or defense evasion, whether or not any of 30 public jailbreak techniques were used.
- Biology and chemistry. Previously Anthropic blocked only a narrow selection of bioweapons queries; that is "no longer certain... enough," given well-resourced malicious actors and models' growing real-world scientific ability. The worked example: predicting how a genetic modification affects adeno-associated virus (AAV) capsid assembly — Mythos-class models outperformed dedicated protein-language models using biological reasoning alone, without being trained for it (see Autonomous Scientific Discovery). Because the same skill that aids gene therapy could design dangerous viruses, Fable currently falls back to Opus 4.8 on most biology/chemistry requests — deliberately over-broad, to be narrowed later.
- Distillation. Requests flagged as attempts to distill Fable 5's capabilities into competing models (a known large-scale extraction threat, especially toward "authoritarian countries") fall back to Opus 4.8. The risk is indirect proliferation of near-frontier capability without the corresponding safeguards.
Robustness (red-teaming)#
The classifiers extend Anthropic's prior constitutional-classifiers line (see Agentic Prompt Injection) with broader coverage, and were stress-tested against jailbreaks:
- An external bug bounty produced no universal jailbreaks in over 1,000 hours of testing.
- External red-teaming orgs "failed to find any universal jailbreaks on long-form agentic tasks so far" — although the UK AISI made progress toward one within a brief initial window.
- Anthropic concedes it is "likely impossible to completely prevent universal jailbreaks"; the goal is to make any remaining ones "sufficiently slow and costly that we can detect and prevent them before they are used at scale" — a tedious-vs-impossible framing applied to the safeguard itself.
A universal jailbreak is defined as any prompt/script/harness that lets a user interact with the model "as if its safeguards were not present," as opposed to minor jailbreaks effective only in narrow contexts.
The 30-day retention policy#
Coupled to the safeguards: Anthropic now requires 30-day data retention for all Mythos-class traffic (first- and third-party, including business customers). The data is used only for safety — defending against complex/novel attacks (new jailbreaks, cross-request attacks) and reducing false positives — not for training, with logged human access and deletion after 30 days in almost all cases. A capability threshold thus changes not just the model's guardrails but the data-handling contract around it.
Where it sits#
RSP determines which capabilities need gating (cyber, CB, AI-R&D, misalignment); this architecture is how the cyber/bio gate is implemented at inference for a generally-released model. It is the deployment-time complement to the training-time and policy-level brakes — and the operational answer to the question Mythos Preview left open: how do you ship Mythos-class capability to everyone without shipping the uplift?
Connections#
- Agentic Prompt Injection — Fable's classifiers extend the constitutional-classifier line documented here; jailbreak-robustness is the shared adversarial frame
- Claude Code Auto Mode — the same classifier-gating idea at the tool-call boundary; this page applies it at the query boundary, and swaps a weaker model rather than blocking
- Responsible Scaling Policy Evaluations — the RSP decides what must be gated; this is the inference-time mechanism, and Mythos-class crossing the risk threshold is what forces it
- LLM-Driven Vulnerability Research — the cyber capability the cyber classifier neutralizes; Fable blocks "any progress" on offensive cyber tasks
- Autonomous Scientific Discovery — the bio capability the bio/chem classifier gates; the AAV dual-use example is the motivating case
- Claude Fable 5 — the model that ships these safeguards on
- Claude Mythos 5 — the model with these safeguards lifted; the contrast that defines the two SKUs
- Claude Opus 4.8 — the fallback target; the "far better than refusal" experience rests on it being highly capable in its own right
- Claude Sonnet 5 — a lower-risk point on the same safeguard spectrum: native low cyber capability (no deliberate train-down), inference-time detect-and-block at the Opus-4.7/4.8 strictness level, and no model-swap fallback — Anthropic judged the uplift risk too low to warrant Fable 5's broader classifier-plus-fallback regime
- Impossible, Not Tedious (Design Test) — the safeguard's own success criterion: make jailbreaks slow/costly enough to catch before scaled use
- Open-Weight Elicitation Irreversibility — this entire architecture presupposes a server the vendor controls; an open-weight release forfeits it, along with suspension and retention
- Capability Gating Is Not Authorization — different sense of "capability" — do not conflate. Here, capability = a model's dangerous knowledge level, and the "gate" is a query-level classifier that routes risky prompts to a weaker model (fallback-not-refusal). There, capability = which tools are exposed to an agent, and the thesis is that gating capabilities is not authorizing calls (a tool-call-level per-argument-value check). Same word, orthogonal mechanisms — one routes models by query risk, the other authorizes tool-call arguments against operator policy
Open Questions#
- The >95%/<5% figures are session-level; what's the false-positive rate for legitimate security researchers and biologists, whose benign queries are exactly the ones most likely to trip the conservative classifiers?
- Fallback-not-refusal preserves UX but means the real general-access model for security/bio-adjacent work is Opus 4.8, not Fable — does that quietly cap Fable's value for whole professional segments until the trusted-access programs open?
- The UK AISI's "progress toward a universal jailbreak" is disclosed but not quantified — and the post-launch access suspension (see Claude Fable 5) raises the question of whether a safeguard failure forced it.
- Does swapping to a weaker model on flagged topics create an exploitable oracle (probe which queries trigger fallback to map the classifier's boundary)?
Sources#
- Claude Fable 5 and Claude Mythos 5 — §"Claude Fable 5's new safeguards" (safety classifiers; cyber/bio/distillation coverage; red-teaming; 30-day retention)
Cited by 16
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…
- Autonomous Scientific Discovery
Mythos-class models now conduct novel science with limited human input — autonomous protein/drug design (~10× faster, m…
- Capability Gating Is Not Authorization
Mellafe Zuvic (arXiv 2606.28679): popular agent frameworks (LangChain/LangGraph, LlamaIndex, Stripe Agent Toolkit) ship…
- Claude Code Auto Mode
Claude Code permission mode using a classifier to auto-approve safe tool calls and block risky ones; middle ground betw…
- Claude Fable 5
Anthropic's first generally-available Mythos-class model (June 2026) — state-of-the-art on nearly all benchmarks; the s…
- Claude Mythos 5
The safeguards-lifted form of Claude Fable 5 (June 2026): same underlying Mythos-class model, deployed through Project…
- Claude Opus 4.8
Anthropic's most capable general-access model (May 2026); upgrade on Opus 4.7 in SWE/agentic/knowledge work; does not a…
- Claude Sonnet 5
Anthropic's most agentic Sonnet yet (July 2026); narrows the gap to Opus 4.8 at lower price via effort-level cost-perfo…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- Superintelligence Trajectory
Map of Content for the superintelligence-trajectory domain — 20 concepts. The path from AGI to ASI: recursive self-impr…
- Mythos Model
Anthropic preview-tier frontier model and the first member of the Mythos-class tier (above Opus); gated for safety, use…
- Open Questions Backlog
_396 actionable open questions across 155 pages · 79 predictions · 9 notes · 21 in progress · 59 watching (entities), a…
- Open-Weight Elicitation Irreversibility
A wiki-drawn synthesis of Brown and Gemma 4: if dangerous capability scales with inference budget, then an open-weight…
- Responsible Scaling Policy Evaluations
Anthropic's RSP gates deployment on pre-release capability evaluations in CBRN, automated AI R&D, and high-stakes misal…
- UK AI Security Institute
UK government AI-evaluation body (Science of Evaluation team); its July 2026 test-time-compute study is the first indep…
Related articles
- Responsible Scaling Policy Evaluations
Anthropic's RSP gates deployment on pre-release capability evaluations in CBRN, automated AI R&D, and high-stakes misal…
- Claude Sonnet 5
Anthropic's most agentic Sonnet yet (July 2026); narrows the gap to Opus 4.8 at lower price via effort-level cost-perfo…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- Anthropic
AI safety company / vendor of Claude; mission-as-tiebreaker culture; ~30–40 PMs across teams; Mike Krieger leads Labs r…
- Claude Fable 5
Anthropic's first generally-available Mythos-class model (June 2026) — state-of-the-art on nearly all benchmarks; the s…